이어서 MariaDB(마리아디비)에서 String Data Types(문자형 데이터 타입)에서 TEXT들은 PreparedStatement에서 어떤 메소드로 값으로 설정해야 하는지 확인해 보겠습니다.
TINYTEXT - 아주 작은 텍스트
TINYTEXT [CHARACTER SET charset_name] [COLLATE collation_name]
최대 길이는 255입니다. (1 character = 1Byte)
유효 최대 길이는 사용되는 Charset에 따라 달라집니다.
Charset이 UTF8이면 한글은 문자당 최대 3Byte가 필요함으로 한글만 입력할 경우 최대 유효 최대 길이는 85입니다. 입력된 문자열에 멀티바이트 문자(한글)가 포함된 경우 유효 최대 길이가 짧아지는 것을 고려해야 합니다.
저장할 때 공백은 제거되지 않습니다.
CREATE TABLE DAT_TEST12_TB (
COL_TINYTEXT1 tinytext,
COL_TINYTEXT2 tinytext CHARACTER SET utf8,
COL_TINYTEXT3 tinytext CHARACTER SET utf8 COLLATE 'utf8_general_ci'
);테스트를 위해 테이블을 생성할 때 Charset을 설정하지 않고 컬럼에 CHARACTER SET과 COLLATE를 설정하였습니다. 테이블에 Charset을 설정하지 않으면 기본적으로 Charset은 "lantin1", Collation은 "latin1_swedish_ci"이 됩니다.
CHARACTER SET은 문자들을 정의한 집합입니다.
COLLATE은 문자 집합의 정렬 방식입니다.
String query = "INSERT INTO DAT_TEST12_TB (COL_TINYTEXT1, COL_TINYTEXT2, COL_TINYTEXT3) VALUES (?, ? ,?)";
PreparedStatement에서는 아주 작은 텍스트인 tinytext 타입을 설정할 수 있는 setString()메소드를 사용하시면 됩니다.
String data1 = "hello";
String data2 = " 안녕하세요. ";
String data3 = "홍길동님, 안녕하세요.";
preparedStatement = connection.prepareStatement(query);
preparedStatement.setString(1, data1);
preparedStatement.setString(2, data2);
preparedStatement.setString(3, data3);
SELECT 쿼리문으로 가져올때 getString()으로 가져옵니다.
테스트를 위해 getString() 메소드에 컬럼 인덱스 대신 컬럼 레이블을 사용하였습니다.
String query = "SELECT COL_TINYTEXT1 AS tinytext1, COL_TINYTEXT2 AS tinytext2, COL_TINYTEXT3 AS tinytext3 FROM DAT_TEST12_TB";
PreparedStatement preparedStatement1 = connection.prepareStatement(query1);
ResultSet resultSet = preparedStatement1.executeQuery();
if (resultSet.next()) {
String data1 = resultSet.getString("tinytext1");
String data2 = resultSet.getString("tinytext2");
String data3 = resultSet.getString("tinytext3");
System.out.println("tinytext1 := \"" + data1 + "\"");
System.out.println("tinytext2 := \"" + data2 + "\"");
System.out.println("tinytext3 := \"" + data3 + "\"");
}
resultSet.close();tinytext1 := "hello"
tinytext2 := " 안녕하세요. "
tinytext3 := "홍길동님, 안녕하세요."
COL_TINYTEXT2 처럼 앞/뒤 공백을 포함해서 저장됩니다.

TINYTEXT는 문자 길이(수)가 아닌 Byte으로 계산됩니다.
SELECT LENGTH(COL_TINYTEXT1), LENGTH(COL_TINYTEXT2), LENGTH(COL_TINYTEXT3) FROM DAT_TEST12_TB;LENGTH(COL_TINYTEXT1)|LENGTH(COL_TINYTEXT2)|LENGTH(COL_TINYTEXT3)|
---------------------+---------------------+---------------------+
5| 22| 30|COL_TINYTEXT1는 영문자 5개(1Byte * 5 = 5Byte)로 5Byte입니다.
COL_TINYTEXT2는 앞/뒤 공백 6개(1Byte * 6 = 6Byte)와 마침표 1개(1Byte * 1 = 1Byte), 한글 5개(3Byte * 5 = 15Byte)로 22Byte입니다.
COL_TINYTEXT3는 공백 1개(1Byte * 1 = 1Byte)와 쉼표/마침표 각각 1개(1Byte * 2 = 2Byte), 한글 9개(3Byte * 9 = 27Byte)로 30Byte입니다.
다음 처럼 영문자는 255자(1Byte = 255 Byte)가 입력되고 한글은 85자(3Byte = 255Byte)가 입력됩니다. 그러나 한글은 86자(3Byte = 258Byte)를 입력하면 범위를 벗어남으로 java.sql.SQLException으로 "Data too long for column" 에러가 발생합니다.
INSERT INTO DAT_TEST12_TB (COL_TINYTEXT1, COL_TINYTEXT2, COL_TINYTEXT3)
VALUES (RPAD('', 255, 'x'), RPAD('', 85, '가'), LPAD('', 86, '나'));SQL Error [1406] [22001]: (conn=8) Data too long for column 'COL_TINYTEXT3' at row 1
TEXT - 텍스트
TEXT[(M)] [CHARACTER SET charset_name] [COLLATE collation_name]
Range(길이) : 1 ~ 65,535 (1 character = 1Byte)
(M)의 유효 최대 길이는 사용되는 Charset에 따라 달라집니다.
Charset이 UTF8이면 한글은 문자당 최대 3Byte가 필요함으로 한글만 입력할 경우 최대 Range(길이)는 21,845입니다. 입력된 문자열에 멀티바이트 문자(한글)가 포함된 경우 유효 최대 길이가 짧아지는 것을 고려해야 합니다.
저장할 때 공백은 제거되지 않습니다.
CREATE TABLE DAT_TEST13_TB (
COL_TEXT1 text(10),
COL_TEXT2 text(10) CHARACTER SET utf8,
COL_TEXT3 text(21845) CHARACTER SET utf8 COLLATE 'utf8_general_ci'
);테스트를 위해 테이블을 생성할 때 Charset을 설정하지 않고 컬럼에 CHARACTER SET과 COLLATE를 설정하였습니다.
위와 같이 TEXT의 최대 Range인 21,845를 설정해도 "Row size too large"에러가 발생하지 않습니다.
TEXT는 VARCHAR와 다른게 행(row)의 최대 크기에 영향을 주지 않습니다.
테이블을 생성하고 DBeaver를 통해 확인하면 COL_TEXT1의 text(10)이 tinytext으로 변경되었고 COL_TEXT3의 text(21845)도 text로 변경된 것을 확인할 수 있습니다.
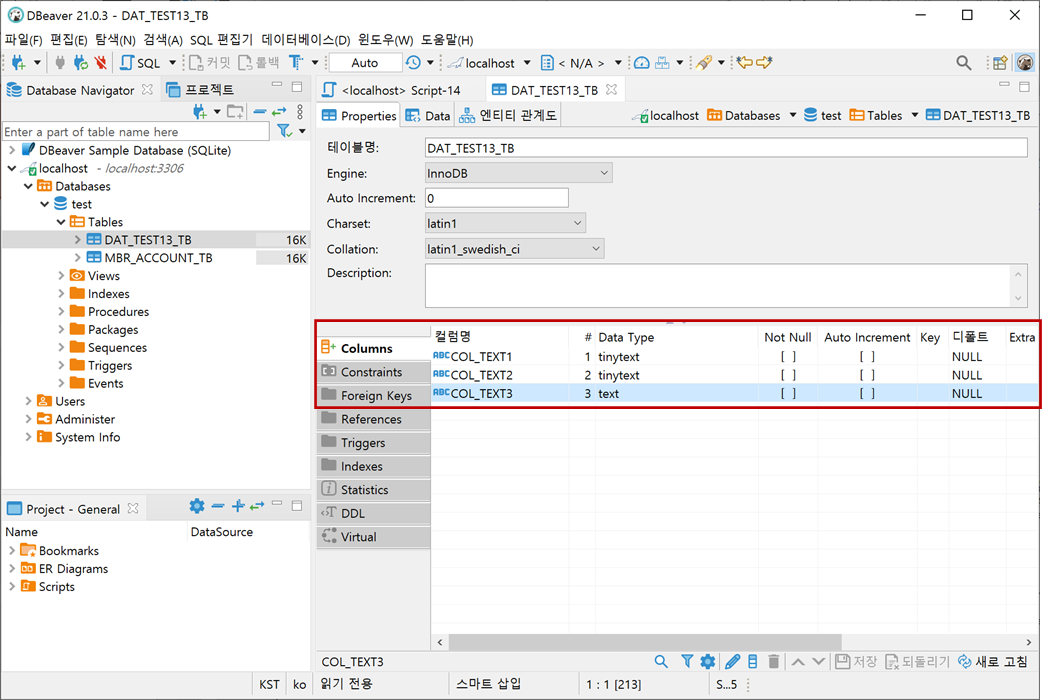
CREATE TABLE DAT_TEST13_TB (
COL_TEXT1 tinytext DEFAULT NULL,
COL_TEXT2 tinytext CHARACTER SET utf8 DEFAULT NULL,
COL_TEXT3 text CHARACTER SET utf8 DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=latin1그 이유는 테이블을 생성할 때 (M)의 길이를 충분히 저장할 수 있는 크기의 TEXT 유형으로 변경하여 생성되기 때문입니다.
즉, COL_TEXT1 text(10)은 (M)이 길이가 "10"으로 "255"까지 저장할 수 있는 tinytext으로 변경된 것이고 COL_TEXT3 text(21845)은 (M)이 길이가 "21845"으로 TEXT 최대 길이인 655,535와 같음으로 text으로 유지됩니다. 타입이 변경되고 (M)은 없어집니다. (COL_TEXT3는 Charset이 UTF8임으로 문자당 최대 3Byte로 계산됩니다.)
TEXT 유형은 (M)의 길이에 따라 자동으로 다른 TEXT 유형으로 변경됩니다.
만약, COL_TEXT3 text(21846)이라면 TEXT 최대 길이인 655,535를 넘어감으로 mediumtext으로 변경됩니다.
TINYTEXT, MEDIUMTEXT, LONGTEXT은 최대 길이로 지정되어 있기 때문에 (M)이 없습니다.
String query = "INSERT INTO DAT_TEST13_TB (COL_TEXT1, COL_TEXT2, COL_TEXT3) VALUES (?, ? ,?)";
PreparedStatement에서는 텍스트인 text 타입을 설정할 수 있는 setString()메소드를 사용하시면 됩니다.
String data1 = "hello";
String data2 = " 안녕하세요. ";
String data3 = "홍길동님, 안녕하세요.";
preparedStatement = connection.prepareStatement(query);
preparedStatement.setString(1, data1);
preparedStatement.setString(2, data2);
preparedStatement.setString(3, data3);위의 data2처럼 COL_TEXT2가 tinytext으로 타입 유형이 변경되어 22Byte인 문자열이 문제없이 등록됩니다.
SELECT 쿼리문으로 가져올때 getString()으로 가져옵니다.
테스트를 위해 getString() 메소드에 컬럼 인덱스 대신 컬럼 레이블을 사용하였습니다.
String query = "SELECT COL_TEXT1 AS text1, COL_TEXT2 AS text2, COL_TEXT3 AS text3 FROM DAT_TEST13_TB";
PreparedStatement preparedStatement = connection.prepareStatement(query);
ResultSet resultSet = preparedStatement.executeQuery();
if (resultSet.next()) {
String data1 = resultSet.getString("text1");
String data2 = resultSet.getString("text2");
String data3 = resultSet.getString("text3");
System.out.println("text1 := \"" + data1 + "\"");
System.out.println("text2 := \"" + data2 + "\"");
System.out.println("text3 := \"" + data3 + "\"");
}
resultSet.close();text1 := "hello"
text2 := " 안녕하세요. "
text3 := "홍길동님, 안녕하세요."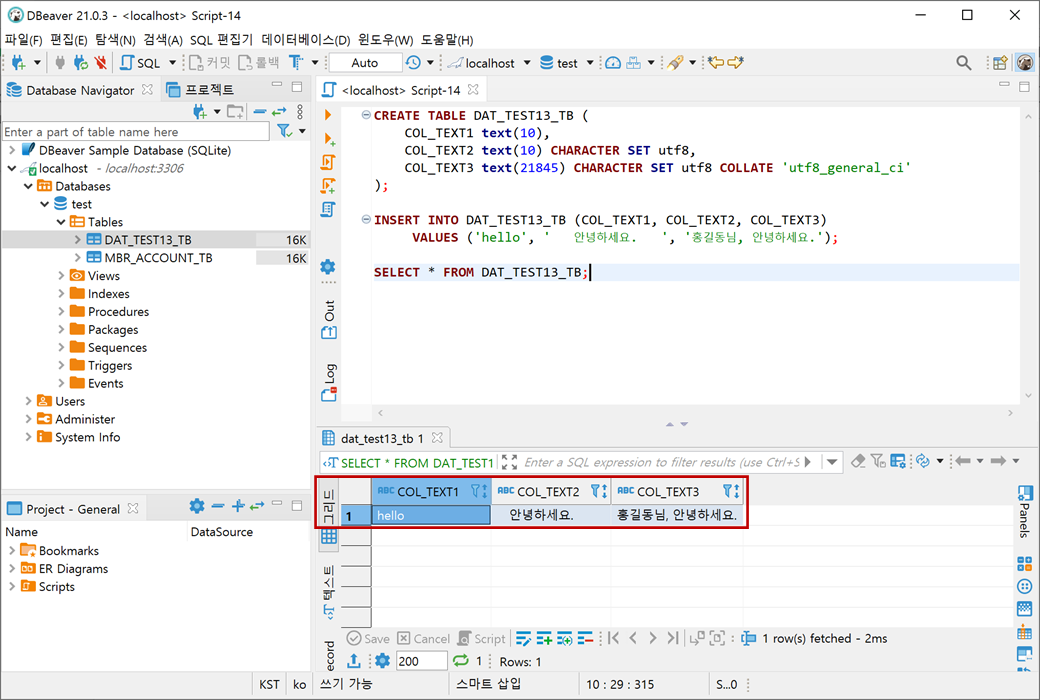
이어서 대용량 텍스트를 처리하는 방법에 대해 알아보겠습니다.