MariaDB(마리아디비)에서 String Data Types(문자형 데이터 타입)별로 PreparedStatement에서 어떤 메소드로 값으로 설정해야 하는지 확인해 보겠습니다.
CHAR - 고정 길이 문자열(fixed-length string)
CHAR(M)
Range(길이) : 0 ~ 127
(M)은 Byte가 아닌 문자 길이(수)입니다.
저장할 때 지정된 길이(M)만큼 공백이 항상 오른쪽으로 채워집니다.
(M)을 설정하지 않으면 1로 설정됩니다.
CREATE TABLE DAT_TEST10_TB (
COL_CHAR1 char(1),
COL_CHAR2 char(1),
COL_CHAR3 char(10)
) DEFAULT CHARSET=utf8;String query = "INSERT INTO DAT_TEST10_TB (COL_CHAR1, COL_CHAR2, COL_CHAR3) VALUES (?, ? ,?)";
PreparedStatement에서는 고정 길이 문자열인 char 타입을 설정할 수 있는 setObject()메소드나 setString()메소드를 사용하시면 됩니다.
char data1 = 'H';
char data2 = 'h';
String data3 = "안녕하세요.";
preparedStatement = connection.prepareStatement(query);
preparedStatement.setObject(1, data1, java.sql.Types.CHAR);
preparedStatement.setString(2, String.valueOf(data2));
preparedStatement.setString(3, data3);
만약, 테이블의 Charset이 UTF8이 아닌 경우 "Incorrect string value"에러가 발생합니다.
java.sql.SQLSyntaxErrorException: (conn=133) Incorrect string value: '\xED\x99\x8D\xEA\xB8\xB8...' for column `test`.`dat_test10_tb`.`COL_CHAR3` at row 1
Caused by: org.mariadb.jdbc.internal.util.exceptions.MariaDbSqlException: Incorrect string value: '\xED\x99\x8D\xEA\xB8\xB8...' for column `test`.`dat_test10_tb`.`COL_CHAR3` at row 1
Caused by: java.sql.SQLException: Incorrect string value: '\xED\x99\x8D\xEA\xB8\xB8...' for column `test`.`dat_test10_tb`.`COL_CHAR3` at row 1위에서 테이블 생성시 테이블의 Charset이 UTF8로 설정하였기 때문에 에러는 발생하지 않습니다.
만약, COL_CHAR1이 char(0)일 경우 열(컬럼)은 존재하지만 그 값은 사용하지 않게 됩니다. 그레서 "NULL"이나 공백으로 입력하시면 됩니다.
preparedStatement.setNull(1, java.sql.Types.NULL);
preparedStatement.setString(1, "");
한글 문자열 길이 가져오기
LENGTH vs CHAR_LENGTH
SELECT LENGTH(COL_CHAR1), LENGTH(COL_CHAR2), LENGTH(COL_CHAR3) FROM DAT_TEST10_TB;LENGTH(COL_CHAR1)|LENGTH(COL_CHAR2)|LENGTH(COL_CHAR3)|
-----------------+-----------------+-----------------+
1| 1| 16|
LENGTH 함수는 문자의 Byte 길이를 가져오기 때문에 한글 한글자는 3Byte로 가져옵니다.
그래서 문자의 길이를 가져오는 CHAR_LENGTH 함수를 사용하면 됩니다.
SELECT CHAR_LENGTH(COL_CHAR1), CHAR_LENGTH(COL_CHAR2), CHAR_LENGTH(COL_CHAR3) FROM DAT_TEST10_TB;CHAR_LENGTH(COL_CHAR1)|CHAR_LENGTH(COL_CHAR2)|CHAR_LENGTH(COL_CHAR3)|
----------------------+----------------------+----------------------+
1| 1| 6|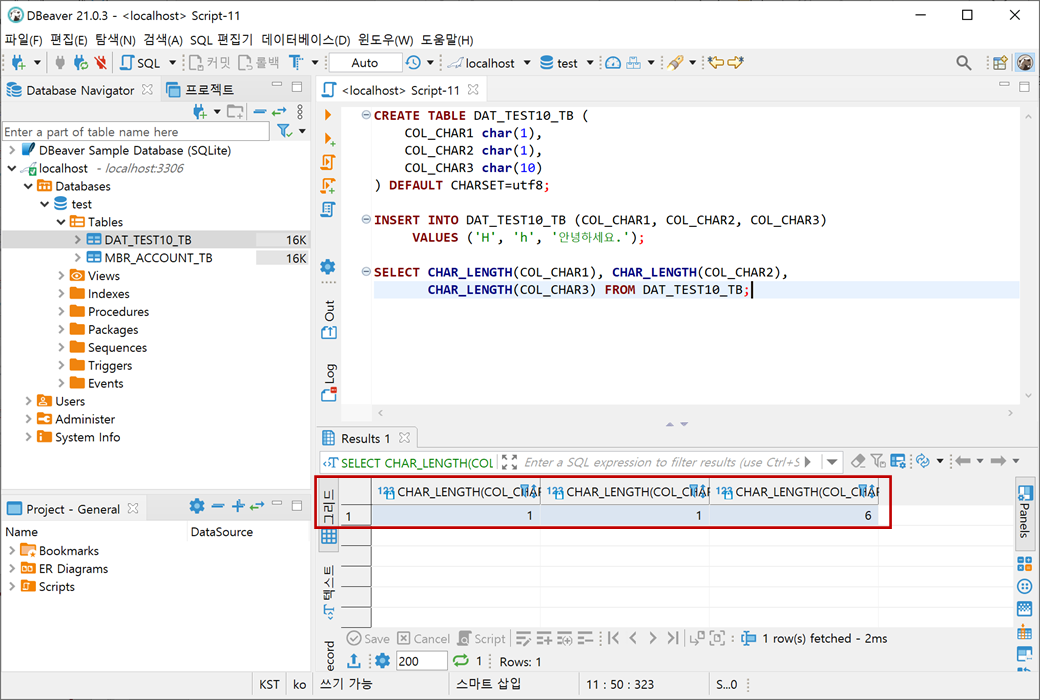
여기서 이상한 점을 발견하셨나요?
COL_CHAR3의 문자 길이가 6이 나왔습니다. COL_CHAR3가 CHAR(10)로 설정하였기 때문에 10이 나와야 하는데 말입니다. 그리고 결과를 보면 공백도 추가되어 있지 않습니다.
그 이유는 MariaDB에서 기본적으로 SELECT시 CHAR 값을 검색할 때 후행 공백은 제거됩니다. 실제 데이터는 공백이 포함되어 있습니다.
SELECT시 CHAR 후행 공백 표시하기
MariaDB에서 PAD_CHAR_TO_FULL_LENGTH인 SQL 모드가 활성화되어 있지 않으면 CHAR 값을 SELECT할 때 후행 공백은 제거됩니다. 기본적으로 PAD_CHAR_TO_FULL_LENGTH은 활성화 되어 있지 않습니다.
PAD_CHAR_TO_FULL_LENGTH을 활성화 시킵니다.
SET sql_mode = 'PAD_CHAR_TO_FULL_LENGTH';
다시 쿼리문을 실행하면 COL_CHAR3의 문자 길이가 10으로 나옵니다.
SELECT CHAR_LENGTH(COL_CHAR1), CHAR_LENGTH(COL_CHAR2), CHAR_LENGTH(COL_CHAR3) FROM DAT_TEST10_TB;CHAR_LENGTH(COL_CHAR1)|CHAR_LENGTH(COL_CHAR2)|CHAR_LENGTH(COL_CHAR3)|
----------------------+----------------------+----------------------+
1| 1| 10|
COL_CHAR3의 값도 공백이 있음을 확인할 수 있습니다.
SELECT REPLACE(COL_CHAR3, ' ', 'x') FROM DAT_TEST10_TB;REPLACE(COL_CHAR3, ' ', 'x')|
----------------------------+
안녕하세요.xxxx |
MariaDB에 SQL 모드 설정하기
1. 마리아디비(MariaDB) 설치 폴더에서 data폴더의 my.ini파일 메모장을 이용하여 오픈합니다.
마리아디비(MariaDB)가 기본 설정으로 설치하였다면 C:\Program Files\MariaDB 10.5로 되어 있습니다.
2. my.ini파일을 오픈합니다.
[mysql]섹터의 마지막에 sql_mode를 추가하고 저장합니다.
sql_mode="PAD_CHAR_TO_FULL_LENGTH"
3. 윈도우 "시작"(start)버튼을 클릭하고 "스페이스 바"(Space Bar)을 클릭합니다. 입력창에 "서비스"입력 후 "서비스"를 클릭합니다.
마리아디비(MariaDB) 서비스를 다시 시작하기 위해 "MariaDB"를 찾아 선택하고 "다시 시작"를 클릭합니다.
SQL 모드 확인하기
쿼리문을 통해 확인할 수 있습니다.
SELECT @@sql_mode;IGNORE_SPACE,STRICT_TRANS_TABLES,PAD_CHAR_TO_FULL_LENGTHPAD_CHAR_TO_FULL_LENGTH가 추가되어 있는 것을 확인할 수 있습니다.
범위를 벗어나다면 java.sql.SQLException으로 "Data too long for column" 에러가 발생합니다.
char data1 = 'H';
char data2 = 'h';
String data3 = "홍길동님, 안녕하세요."; // Error 유발
preparedStatement = connection.prepareStatement(query);
preparedStatement.setObject(1, data1, java.sql.Types.CHAR);
preparedStatement.setString(2, String.valueOf(data2));
preparedStatement.setString(3, data3);java.sql.SQLSyntaxErrorException: (conn=69) Data too long for column 'COL_CHAR3' at row 1
Caused by: org.mariadb.jdbc.internal.util.exceptions.MariaDbSqlException: Data too long for column 'COL_CHAR3' at row 1
Caused by: java.sql.SQLException: Data too long for column 'COL_CHAR3' at row 1
SELECT 쿼리문으로 가져올때 getString()으로 가져옵니다.
String query = "SELECT COL_CHAR1 AS char1, COL_CHAR2 AS char2, COL_CHAR3 AS char3 FROM DAT_TEST10_TB";
PreparedStatement preparedStatement = connection.prepareStatement(query);
ResultSet resultSet = preparedStatement.executeQuery();
if (resultSet.next()) {
char data1 = resultSet.getString(1).charAt(0);
String data2 = resultSet.getString(2);
String data3 = resultSet.getString(3);
System.out.println("char1 := \"" + data1 + "\"");
System.out.println("char2 := \"" + data2 + "\"");
System.out.println("char3 := \"" + data3 + "\"");
}
resultSet.close();char1 := "H"
char2 := "h"
char3 := "안녕하세요. "
VARCHAR - 가변 길이 문자열(variable-length string)
VARCHAR(M) [CHARACTER SET charset_name] [COLLATE collation_name]
Range(길이) : 0 ~ 65,532
VARCHAR는 CHARACTER VARYING의 약어입니다.
(M)의 유효 최대 길이는 사용되는 Charset에 따라 달라집니다.
Charset이 UTF8이면 한글은 문자당 최대 3바이트가 필요함으로 한글만 입력할 경우 (M)의 최대 Range(길이)는 21,844입니다.
저장할 때 공백은 제거되지 않습니다.
CREATE TABLE DAT_TEST11_TB (
COL_VARCHAR1 varchar(10),
COL_VARCHAR2 varchar(10) CHARACTER SET utf8,
COL_VARCHAR3 varchar(20) CHARACTER SET utf8 COLLATE 'utf8_general_ci'
);테스트를 위해 테이블을 생성할 때 Charset을 설정하지 않고 컬럼에 CHARACTER SET과 COLLATE를 설정하겠습니다. 테이블에 Charset을 설정하지 않으면 기본적으로 Charset은 "lantin1", Collation은 "latin1_swedish_ci"이 됩니다.
CHARACTER SET은 문자들을 정의한 집합입니다.
COLLATE은 문자 집합의 정렬 방식입니다.
String query = "INSERT INTO DAT_TEST11_TB (COL_VARCHAR1, COL_VARCHAR2, COL_VARCHAR3) VALUES (?, ? ,?)";
PreparedStatement에서는 가변 길이 문자열인 varchar 타입을 설정할 수 있는 setString()메소드를 사용하시면 됩니다.
String data1 = "hello";
String data2 = "안녕하세요.";
String data3 = "홍길동님, 안녕하세요.";
preparedStatement = connection.prepareStatement(query);
preparedStatement.setString(1, data1);
preparedStatement.setString(2, data2);
preparedStatement.setString(3, data3);
만약, COL_VARCHAR1이 varchar(0)일 경우 열(컬럼)은 존재하지만 그 값은 사용하지 않게 됩니다. 그레서 "NULL"이나 공백으로 입력하시면 됩니다.
preparedStatement.setNull(1, java.sql.Types.NULL);
preparedStatement.setString(1, "");
SELECT 쿼리문으로 가져올때 getString()으로 가져옵니다.
ResultSet에서 컬럼의 값을 가져오는 모든 메소드들은 컬럼 레이블로도 컬럼 값을 가져올 수 있습니다.
테스트를 위해 getString() 메소드에 컬럼 인덱스 대신 컬럼 레이블을 사용하였습니다.
String query = "SELECT COL_VARCHAR1 AS varchar1, COL_VARCHAR2 AS varchar2, COL_VARCHAR3 AS varchar3 FROM DAT_TEST11_TB";
PreparedStatement preparedStatement = connection.prepareStatement(query);
ResultSet resultSet = preparedStatement.executeQuery();
if (resultSet.next()) {
String data1 = resultSet.getString("varchar1");
String data2 = resultSet.getString("varchar2");
String data3 = resultSet.getString("varchar3");
System.out.println("varchar1 := \"" + data1 + "\"");
System.out.println("varchar2 := \"" + data2 + "\"");
System.out.println("varchar3 := \"" + data3 + "\"");
}
resultSet.close();varchar1 := "hello"
varchar2 := "안녕하세요."
varchar3 := "홍길동님, 안녕하세요."
COLLATE(정렬 방식) 테스트
bin vs general
bin은 문자의 바이러니 값을 기준으로 정렬합니다.
general은 문자를 기준으로 정렬합니다.
CREATE TABLE DAT_TEST11_TB (
COL_VARCHAR1 varchar(10) CHARACTER SET utf8 COLLATE 'utf8_bin',
COL_VARCHAR2 varchar(10) CHARACTER SET utf8 COLLATE 'utf8_general_ci'
);INSERT INTO DAT_TEST11_TB (COL_VARCHAR1, COL_VARCHAR2) VALUES ('a', 'a');
INSERT INTO DAT_TEST11_TB (COL_VARCHAR1, COL_VARCHAR2) VALUES ('b', 'b');
INSERT INTO DAT_TEST11_TB (COL_VARCHAR1, COL_VARCHAR2) VALUES ('A', 'A');
INSERT INTO DAT_TEST11_TB (COL_VARCHAR1, COL_VARCHAR2) VALUES ('B', 'B');
INSERT INTO DAT_TEST11_TB (COL_VARCHAR1, COL_VARCHAR2) VALUES ('1', '1');
INSERT INTO DAT_TEST11_TB (COL_VARCHAR1, COL_VARCHAR2) VALUES ('2', '2');
COLLATE가 bin으로 설정된 COL_VARCHAR1을 기준으로 정렬할 경우 문자의 바이러니 값을 기준으로 정렬됩니다.
SELECT COL_VARCHAR1, HEX(COL_VARCHAR1) FROM DAT_TEST11_TB ORDER BY COL_VARCHAR1 ASC;COL_VARCHAR1|HEX(COL_VARCHAR1)|
------------+-----------------+
1 |31 |
2 |32 |
A |41 |
B |42 |
a |61 |
b |62 |
COLLATE가 general으로 설정된 COL_VARCHAR2을 기준으로 정렬할 경우 문자의 대소문자나 순서와 같은 기준으로 정렬됩니다.
SELECT COL_VARCHAR2, HEX(COL_VARCHAR2) FROM DAT_TEST11_TB ORDER BY COL_VARCHAR2 ASC;COL_VARCHAR2|HEX(COL_VARCHAR2)|
------------+-----------------+
1 |31 |
2 |32 |
a |61 |
A |41 |
b |62 |
B |42 |
입력값이 한글일 경우 COLLATE에 영향이 없지만 영어가 포함된 데이터가 있다면 정렬 기준에 영향이 있습니다.
그 이유는 UTF8의 한글은 완성형 코드를 사용하여 가나다 순으로 되어 있고 대소문자가 없기 때문에 COLLATE에 영향을 받지 않습니다.
INSERT INTO DAT_TEST11_TB (COL_VARCHAR1, COL_VARCHAR2) VALUES ('가', '가');
INSERT INTO DAT_TEST11_TB (COL_VARCHAR1, COL_VARCHAR2) VALUES ('나', '나');
INSERT INTO DAT_TEST11_TB (COL_VARCHAR1, COL_VARCHAR2) VALUES ('다', '다');
SELECT COL_VARCHAR1, HEX(COL_VARCHAR1) FROM DAT_TEST11_TB ORDER BY COL_VARCHAR1 ASC;COL_VARCHAR1|HEX(COL_VARCHAR1)|
------------+-----------------+
가 |EAB080 |
나 |EB8298 |
다 |EB8BA4 |
SELECT COL_VARCHAR2, HEX(COL_VARCHAR2) FROM DAT_TEST11_TB ORDER BY COL_VARCHAR2 ASC;COL_VARCHAR2|HEX(COL_VARCHAR2)|
------------+-----------------+
가 |EAB080 |
나 |EB8298 |
다 |EB8BA4 |
만약, COL_VARCHAR3을 varchar(10)에서 UTF8의 최대 크기인 varchar(21844)로 변경해서 등록하면 "Row size too large"에러가 발생합니다.
CREATE TABLE DAT_TEST11_TB (
COL_VARCHAR1 varchar(10),
COL_VARCHAR2 varchar(10) CHARACTER SET utf8,
COL_VARCHAR3 varchar(21844) CHARACTER SET utf8 COLLATE 'utf8_general_ci'
);그 이유는 MariaDB에서 BLOB 타입을 제외하고 행(row)의 최대 크기(컬럼 전체 합)는 65,535입니다. 그래서 전체 컬럼의 크기가 65,535를 넘어가면 에러가 발생하여 생성되지 않습니다. (10 + (10 * 3) + (3 * 21,844) = 65,572)
SQL Error [1118] [42000]: (conn=121) Row size too large.
The maximum row size for the used table type, not counting BLOBs, is 65535.
This includes storage overhead, check the manual.
You have to change some columns to TEXT or BLOBs그레서 일부 컬럽의 타입을 TEXT나 BLOB를 변경하라고 알려줍니다.
테이블에 컬럼이 하나면 최대 크기를 사용할 수 있지만 여러 컬럼이라면 행(row)의 최대 크기를 고려해서 설정해야 합니다.